
Invertir en un rediseño web impecable, una infraestructura de servidores ultrarrápida o una producción de contenidos constante no sirve de nada si los motores de búsqueda deciden ignorar tus páginas. Dar por sentado que Google descubrirá e indexará cada URL de tu sitio de forma automática es el camino más directo hacia la invisibilidad. La indexación ya no es una consecuencia pasiva del rastreo: es un filtro técnico y de calidad cada vez más estricto.
En 2026 Google ha lanzado dos Core Updates (en marzo y en mayo) y la búsqueda generativa se ha consolidado. En el sector observamos a un Google cada vez más selectivo con el presupuesto de rastreo (crawl budget): si tu plataforma envía señales técnicas contradictorias, bloquea el renderizado o supera los límites de descarga de los rastreadores, tus páginas dejan de aparecer en las SERP. Esta guía aborda las mecánicas exactas para diagnosticar, solucionar y forzar la indexación con los estándares actuales.
El nuevo paradigma: rastreo frente a indexación
Un error recurrente es confundir el rastreo con la indexación. Son dos fases independientes dentro de los sistemas de Google, y diferenciarlas es indispensable para auditar cualquier caída de tráfico orgánico.
El rastreo (crawling) es la fase de exploración y descarga: Googlebot solicita el código de una URL mediante una petición HTTP y lee el archivo para extraer enlaces. Que un bot haya visitado una URL no implica que vaya a mostrarse en los resultados; significa, únicamente, que ha procesado bytes en tu servidor.
La indexación (indexing) es la admisión en la base de datos de Google. Ocurre después de que el sistema de renderizado (Web Rendering Service) procesa el código, ejecuta los scripts y evalúa la calidad del contenido. Si la página cumple las directrices de Search Essentials, aporta valor original y no duplica información existente, se le asigna un espacio en el índice. Solo entonces tu URL empieza a competir por posiciones.
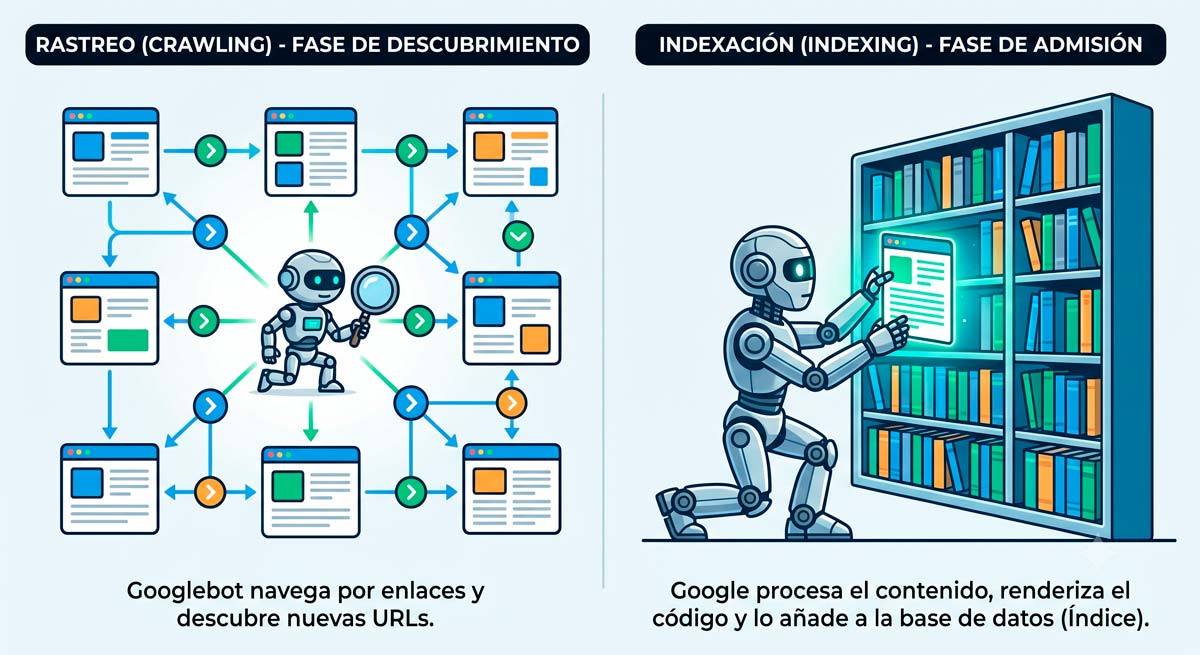
Estar indexado es cumplir el suelo técnico mínimo de tu visibilidad. Es el punto de partida, nunca el techo de una estrategia SEO.
El límite de 2 MB: cuando Googlebot deja de leer tu HTML
Una restricción técnica clave —y documentada por Google— es el límite de descarga por archivo. Para los archivos HTML, Googlebot rastrea solo los primeros 2 MB del documento sin comprimir (otros tipos de archivo tienen límites mayores). Si el HTML supera ese umbral, el resto se descarta.
Si el código HTML de tu página supera los 2 MB por culpa de megamenús con miles de enlaces, CSS crítico incrustado de forma ineficiente o bloques masivos de JSON-LD, Googlebot corta la lectura en torno a los 2 millones de bytes. Todo el contenido, los enlaces internos o las etiquetas canónicas que queden por debajo de ese punto, simplemente, no existen para Google.
Para comprobar el peso neto de tu HTML sin compresión de red, ejecuta este comando en tu terminal:
curl -s -H "Accept-Encoding: identity" https://tudominio.com/pagina-critica | wc -cSi el resultado supera los 2.000.000 de bytes, estás en zona de riesgo. La solución pasa por externalizar los scripts pesados, modularizar las hojas de estilo y limpiar el árbol DOM reduciendo nodos innecesarios.
Cómo diagnosticar el estado real de tus URLs sin caer en mitos
El comando site:tudominio.com en el buscador público es impreciso: ofrece una estimación estadística que a menudo induce a conclusiones erróneas.
La fuente de verdad para monitorizar cómo interactúa Google con tu sitio es Google Search Console. Con la herramienta de inspección de URLs auditas el estado del índice y ves, con precisión:
- Qué agente de Googlebot hizo la solicitud (smartphone o desktop).
- El código de respuesta HTTP que devolvió tu servidor.
- La URL canónica declarada por ti frente a la que seleccionó Google.
- Si robots.txt permitió el rastreo.
Anatomía de los errores de indexación en Search Console
El informe de indexación de páginas es el cuadro de mando donde se concentran los problemas. Para resolverlos, primero hay que entender la raíz de cada estado de exclusión.

Descubierta: actualmente sin indexar
Google ha encontrado la URL (por el sitemap o un enlace interno), pero ha pospuesto su rastreo: ni siquiera ha hecho una petición HTTP para descargarla. La causa habitual es un problema de presupuesto de rastreo o un tiempo de respuesta del servidor (TTFB) alto. Si tu servidor tarda demasiado, Google reduce la frecuencia para no sobrecargarlo. Solución: optimizar el rendimiento del servidor, implementar caché en el borde (edge caching) y reforzar el enlazado interno desde tus páginas con más autoridad.
Rastreada: actualmente sin indexar
Aquí es al revés: Googlebot ha descargado el HTML, pero ha decidido no incluir la página en el índice. No es un fallo de red; es un veredicto sobre el valor del contenido. Suele pasar en categorías de e-commerce casi idénticas, fichas de producto con descripciones genéricas del fabricante o posts que replican información de terceros. Solución: fusionar contenidos similares mediante redirecciones y enriquecer las páginas estratégicas con datos propios, tablas de especificaciones y elementos originales.
Duplicada: el usuario no la ha seleccionado como canónica
Ocurre cuando declaras una URL preferida con rel="canonical" pero Google elige otra como principal. La etiqueta canonical es una sugerencia, no una directiva obligatoria. Si tu menú o tus sitemaps apuntan a una URL parametrizada o alternativa, Google ignorará tu etiqueta. Solución: auditar la coherencia del enlazado interno y que todas las referencias apunten a la URL canónica absoluta.
Error soft 404
Es una incoherencia entre servidor y buscador: la página devuelve un 200 OK a nivel de red, pero el contenido es una página de error, una categoría vacía o un documento sin texto útil. Google interpreta que intentas indexar un cascarón vacío y la bloquea. Solución: que el servidor devuelva un 404 Not Found real si no hay contenido válido, o un 301 Moved Permanently hacia un recurso relevante.
Excluida por "noindex" o bloqueada por robots.txt
Son directivas explícitas. "Excluida por noindex" significa que tu código contiene <meta name="robots" content="noindex">. "Bloqueada por robots.txt" indica que las reglas del archivo raíz prohíben el acceso a esa ruta. Si afecta a páginas clave de tu embudo, retira la directiva del código o limpia las líneas Disallow incorrectas.
Arquitectura técnica y cuota de rastreo: SSR frente a CSR
La arquitectura de tu web condiciona directamente la eficiencia de su indexación. Las plataformas basadas exclusivamente en renderizado en el cliente (CSR) con frameworks JavaScript puros (React, Angular o Vue sin SSR) presentan problemas de indexación a gran escala.
Ante una web CSR, Googlebot recibe un HTML casi vacío y un lote de JavaScript pesado. Debe pausar el procesamiento y enviar la página a una cola del Web Rendering Service para ejecutar los scripts y ver el contenido. Ese segundo paso consume más cuota de rastreo y retrasa la indexación.
Para una indexación fluida, lo recomendable es renderizado en el servidor (SSR) o generación estática (SSG). Al entregar el HTML ya estructurado desde la primera respuesta, Googlebot procesa contenido y enlaces al instante, sin esperar en colas de renderizado.
Caso real: nuestra migración de WordPress a Astro
Para ilustrar el impacto de la arquitectura en la indexación, usamos nuestro propio caso: la migración de consultoriaseosevilla.es de WordPress a Astro. El punto de partida en Search Console era claro y mejorable: 143 URLs indexadas frente a 404 no indexadas.
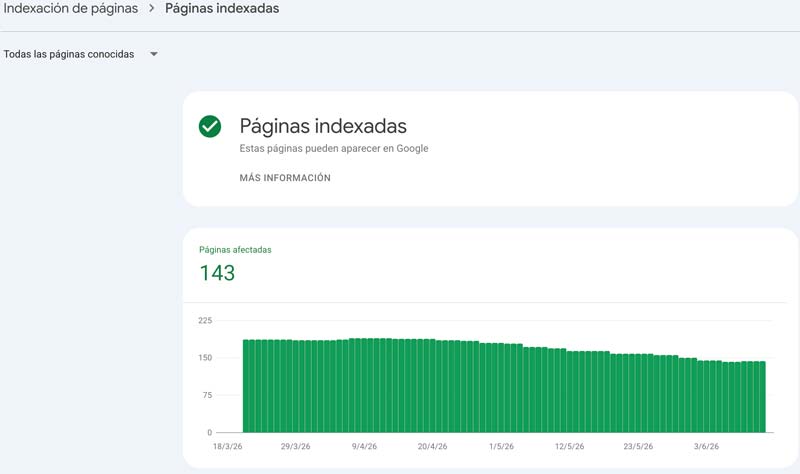
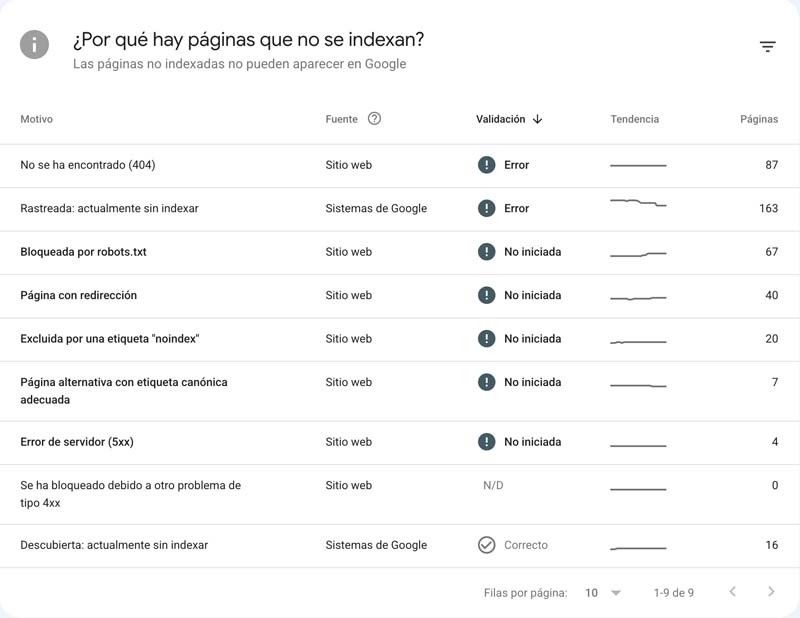
El grueso de las URLs no indexadas se repartía entre "Rastreada: actualmente sin indexar" (163), "No encontrada (404)" (87), bloqueadas por robots.txt (67) y páginas con redirección (40). La mayoría de los 404 eran URLs antiguas de WordPress que la migración había dejado sin redirección.
Pero no todas esas exclusiones eran un problema: aprovechamos la migración para hacer limpieza. Eliminamos decenas de posts antiguos que seguían indexados pero que ya no recibían impresiones ni tráfico en Google y los redirigimos a contenidos vigentes; y actualizamos muchos otros con información nueva. Podar lo obsoleto concentra el presupuesto de rastreo y la autoridad en las páginas que de verdad importan. Eso sí, al renovar a fondo un contenido es normal que Google tarde un tiempo en volver a indexarlo y reasentar sus posiciones.
El plan de trabajo (en ejecución) ha consistido en:
- Migración a Astro (estático): HTML ligero servido desde la primera respuesta, sin depender de renderizado en cliente.
- Mapa de redirecciones 301 1:1: mapeamos las URLs WP antiguas y configuramos las 301 hacia su equivalente actual (más de 300 reglas en total), además de corregir un bucle de redirección hacia una página inexistente.
- Poda y actualización de contenido: eliminamos decenas de posts obsoletos que ya no generaban tráfico (con su redirección correspondiente) y renovamos otros muchos con contenido actualizado, para concentrar la autoridad en lo que de verdad aporta.
- Saneamiento de robots.txt y sitemap: verificamos que no se bloquean páginas valiosas y añadimos al sitemap las que faltaban.
- Realineado del enlazado interno hacia las páginas de servicio prioritarias.
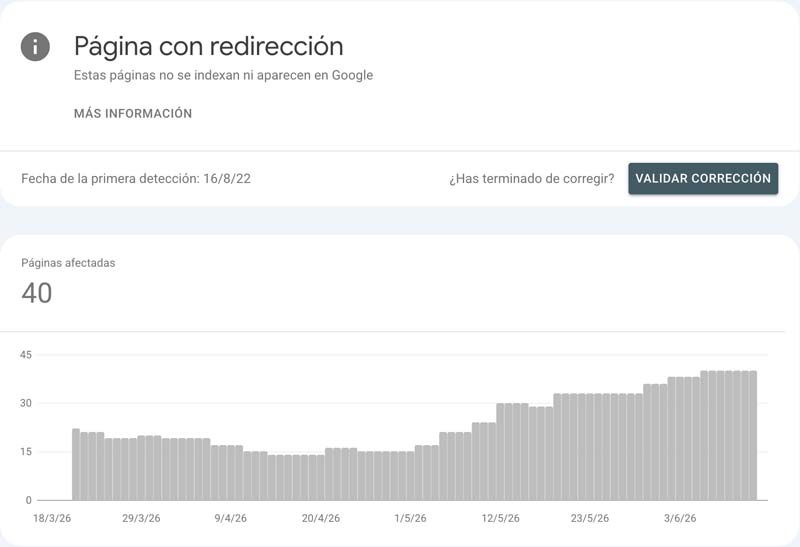
Estado actual: en medición. Los cambios se han desplegado en producción y estamos monitorizando la reindexación en Search Console (validación de errores y rastreo de los nuevos sitemaps). Publicaremos aquí los resultados verificados —indexadas vs. excluidas y evolución del tráfico— cuando dispongamos de datos consolidados tras el reprocesamiento de Google. Preferimos enseñar números reales a prometer cifras.
Automatización: sitemaps, Indexing API e IndexNow
La gestión masiva de la indexación requiere protocolos automatizados, pero aplicarlos sin conocer sus límites es contraproducente.
La Google Indexing API es potente, pero su documentación la limita a páginas con datos estructurados de ofertas de empleo (JobPosting) o eventos en directo (BroadcastEvent), con una cuota por defecto de 200 solicitudes diarias por propiedad. Usarla para blogs o landings que no incluyan esos esquemas no está soportado: Google simplemente lo ignora, así que es una vía poco fiable y desaconsejada para forzar la indexación de contenido editorial.
El protocolo IndexNow es la alternativa "push" para el resto del ecosistema: notifica de forma simultánea a varios motores (Bing, Yandex, Naver, Seznam) sobre la creación, modificación o borrado de URLs, con latencia de segundos. Google no lo procesa de forma nativa, por lo que la estrategia sensata en 2026 es híbrida: sitemap.xml bien optimizado para Google + IndexNow para captar el resto de buscadores.
El impacto de la IA y las AI Overviews en el índice
La integración de modelos de lenguaje en la búsqueda ha elevado el listón de admisión en el índice. El objetivo ya no es solo catalogar páginas, sino alimentar respuestas directas (AI Overviews y AI Mode). Los sitios de contenido genérico o sintético de baja calidad (commodity content) están sufriendo desindexaciones: Google no gasta almacenamiento en réplicas del conocimiento común que su propio modelo puede generar.
Desde junio de 2026, Search Console incluye informes específicos de IA generativa: permiten ver, de forma segregada, las impresiones de tu web en las AI Overviews y el AI Mode (por ahora muestra impresiones, páginas, países, dispositivos y fechas; todavía no clics ni CTR). Para entrar en ese índice privilegiado, tu contenido debe aportar datos de origen empírico, análisis firmados por especialistas verificables y resolver la intención de búsqueda de forma definitiva.
Lista de control para blindar tu índice
Antes de lanzar cualquier actualización, verifica estos requisitos:
- El HTML sin comprimir se mantiene por debajo de 2 MB en todas las secciones críticas.
- robots.txt está en la raíz del dominio y no bloquea el acceso de Googlebot a los CSS o scripts necesarios para renderizar.
- El sitemap.xml contiene solo URLs que devuelven 200 OK y apuntan a su canónica absoluta.
- La web usa SSR o SSG para eliminar las esperas en la cola de renderizado de JavaScript.
- Los errores se gestionan con códigos reales 404 o 410, evitando los soft 404.
El posicionamiento técnico exige precisión, no suposiciones
Tener una web indexada es la cuota de entrada para competir, nunca el techo de tu rendimiento. Resolver las ineficiencias del presupuesto de rastreo, sanear Search Console y estructurar el código respetando los límites de los robots requiere una capacidad analítica que va más allá de instalar plugins.
Tener una web espectacular que no aparece en Google es como tener una tienda cerrada con llave. En Consultoría SEO Sevilla analizamos los logs de tu servidor, optimizamos tu crawl budget y reestructuramos tu código. Si tus URLs están atrapadas en "Rastreada: actualmente sin indexar" o sufres descubiertas sin indexar, puedes empezar por una auditoría SEO técnica o desplegar una estrategia integral de posicionamiento SEO. El tráfico cualificado es predecible cuando tu infraestructura está gobernada por especialistas.
Fuentes
- Google Search Central — Googlebot y límites de rastreo (límite de 2 MB para HTML)
- Google Search Central — Informes de rendimiento de IA generativa en Search Console (junio 2026)
- Search Engine Land — Informes de IA en Search Console
- Search Engine Land — Google May 2026 Core Update
- Google Search Central — Indexing API (JobPosting y BroadcastEvent)
- IndexNow — Documentación oficial del protocolo




